




在云原生技术的广泛普及和实施过程中,笔者接触到的很多用户需求里都涉及到对云原生集群的可观测性要求。实现集群的可观测性,是进行集群安全防护的前提条件。而在可观测性的需求中,集群中容器和容器之间网络流量的可观测性需求是其中一个比较重要的部分。对于容器网络的流量采集,其实施难度是大于传统主机网络的流量采集的。
那么容器网络的复杂度到底在哪里?如何更好的去适配容器网络?这里笔者结合在工作实践中的一些积累,在本文中给出一些关于云原生集群网络流量可观测性的一点思考,希望能起到抛砖引玉的效果。
目前在云隙(自适应微隔离)产品云原生场景适配的过程中,已经遇到过如下的一些 CNI 插件:
上述几类插件是大多数云原生环境中常见的 CNI 插件,并且它们本身也涵盖了容器间网络所使用的大部分技术。而在对以这几类 CNI 插件基础的容器网络进行流量信息采集的过程中,笔者发现并不能用一种模式完成所有的采集功能。例如在有的 CNI 插件中,我们需要把宿主机当作一个网络中转设备,在主机上利用旁路的方式检测容器网络流量的变化情况;而在有的 CNI 插件中,我们没法在宿主机上直接观察到任何容器网络的流量信息,需要进入到容器的网络命名空间中去完成采集工作;甚至在有的 CNI 插件中,我们无法抓到两个容器之间的直接访问关系,必须要配合这个 CNI 插件本身实现的技术原理,通过更多的分析来完成对访问关系的确定。
所以,在进行容器网络流量的可观测性方案实施之前,需要对相关 CNI 插件做进一步的分析,来帮助理解为什么不同的 CNI 插件兼容适配的要求会有不同。
Flannel 是 CoreOS 团队针对 Kubernetes 设计的一个覆盖网络(Overlay Network)CNI 插件。它可以配置为很多种工作模式,目前默认的工作模式是 Vxlan,是一个虚拟的二层网络。
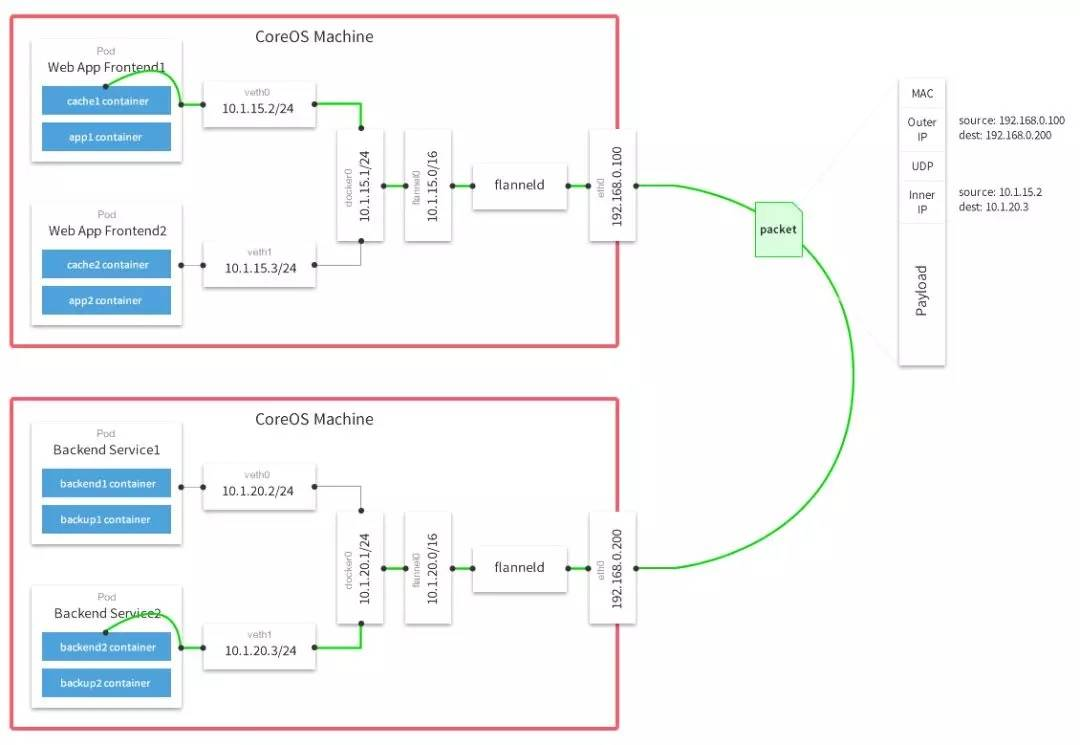 图1
图1
Flannel 是以 DaemonSet 的方式部署在 Kubernetes 集群中。一个完整的 Flannel 架构中包含了如下的一些组件:
总的来说,Flannel 是一个二层的网络解决方案。就其默认的 Vxlan 工作模式来说,可以看作是应用 Vxlan 的分布式网关架构组建了一个二层的通信网络。在这种架构下,宿主机中的虚拟网卡 flannel.1 可以看作是一个作为 Vxlan 二层网关和三层网关的 leaf 节点,而宿主机本身的网卡则可以看作是用于转发的 spine 节点。
 图2
图2
在这种网络环境下,跨界点的容器通信在接收端其实是无法直接抓到来自于发送端的 IP 地址的,因为在三层转发的时候,发送端的 IP 就已经被替换为了网关的地址。如果从旁路的角度来看,宿主机上也无法直接观察到容器间流量。如果能观察到,一般都是节点自身两个容器之间的连接,因为它们本身处于一个二层网络中。同时,在这种环境中,如果使用 SideCar 模式去容器网络命名空间下进行观测,也会发现由于这个虚拟二层网络本身存在三层转发的网关,我们依然无法直接采集到两个容器之间的连接关系。
如果是 host-gw 模式,那么宿主机就会被纯粹配置一个三层转发的网关,虽然不走 Vxlan 这样的隧道了,但是由于三层转发的存在,我们依然无法直接观测到跨节点容器通信的网络关系。
综上所述,在观测基于 Flannel 的网络流量之时,一定要结合 Flannel 的架构本身,将三层网关的转发特性考虑到网络连接关系的梳理过程之中,才能真正地梳理出实际的连接关系。这样的网络架构,也是网络流量观察的一个难点。
Calico 是一套开源的网络和网络安全方案,用于容器、虚拟机、宿主机之间的网络连接,可以用在kubernetes、OpenShift、DockerEE、OpenStrack 等 PaaS 或 IaaS 平台上
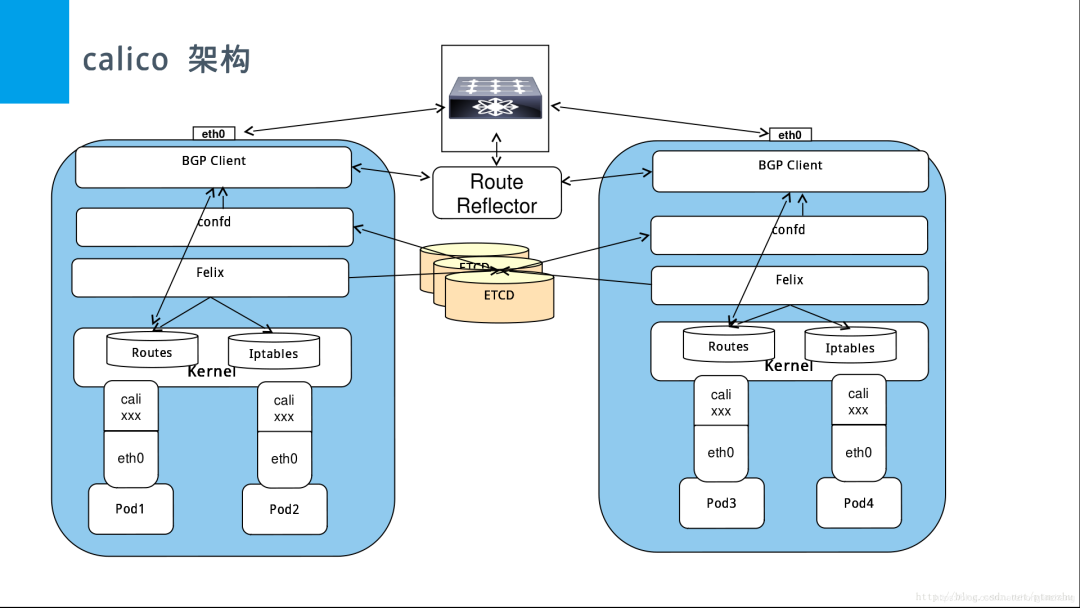 图3
图3
Calico 使用的是 BGP 协议来构建容器间网络,简单来理解就是将集群间的节点当作边界路由来实现整个网络的互通。BGP 协议之下,每一个节点上的所有容器被当作了一个 AS(自治系统),而不同的节点之间,则通过 BGP 服务来进行路由转发实现连通。实际上,Calico 项目提供的 BGP 网络解决方案,与 Flannel 的 Host-GW 模式几乎一样。不同之处在于 Calico 基于路由表实现容器数据包转发,而 Flannel 则使用 flanneld 进程维护路由信息。这里区别在于 flanneld 会介入到路由的转发过程中,导致实际的容器之间通信看起来如同中间会有一个 NAT 服务器的转换(这样的情况下,旁路模式无法直接获取两个容器之间的流量连接关系,需要做一定的推导)。Calico 则是基于内核自己的 BGP 路由转发,本质上还是容器之间原始数据包的投递,所以在宿主机节点上,可以旁路采集到整个容器之间的流量关系。
Calico 为了适配三层网络上运行容器间网络,还增加了对 IPIP 隧道模式的支持。这种模式下,BGP 协议转发的容器网络数据包,会通过内核的 IPIP 模块进行封装然后进行宿主机网络的传送。但是本质上,还是容器和容器 之间的原始通信数据包的传递,没有像 Flannel 那样在跨界点的时候会使用节点 IP 来替换数据包本身发送端的 IP 地址。
Calico 为了灵活适配不同的集群网络规模,提供了全互联模式(Node-to-Node Mesh)和路由反射模式(Router Reflection 简称 RR)。其中全互联模式适用于小规模集群节点,其本身结构简单,易于实现。但是缺点在于 BGP 的连接总数是 “N的平方” ,其中 N 是节点数,在节点增长的情况下,连接数增长会极快带来巨大的网络损耗。而路由反射模式则指定一个或多个 BGP Speaker 为 RouterReflection,这样就减少了连接总数。不过这种架构实现起来更加的复杂,同时对于作为 BGP Speaker 的节点也有更高的要求,适合大型集群的网络规划。
Openshift-SDN 是红帽推出的一款容器集群网络方案,是部署 Openshift 时默认使用的网络方案。可以通过 oc get Network.config.openshift.io cluster -o yaml 命令来查看当前环境使用 CNI 插件。
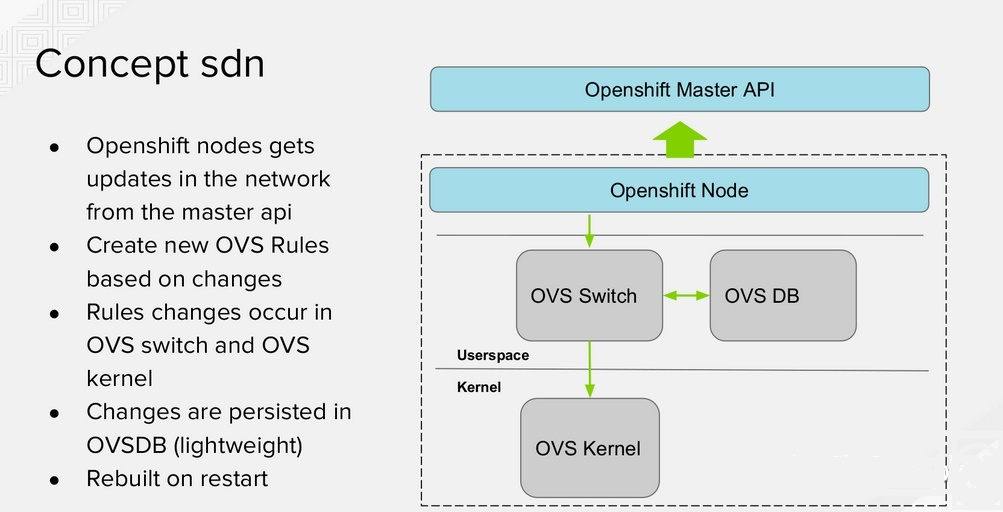 图4
图4
一套 Openshift-SDN 包含了管控面和数据面:
就具体组件来说,主要由 Controller、Agent 以及 CNI 的几个部分构成,它们各自负责的主要内容包括:
① Controller
给新加入的 Node 分配子段,对应 Openshift-SDN 的 CRD :hostSubnet
观察k8s集群中 namespace、networkpolicy 等对象的变更,同步地更新 Openshift-SDN 的 CRD :netnamespaces、egressnetworkpolicies(专门针对出站的networkpolicy)
② Agent
观察集群中 Openshift-SDN 的 CRD :hostSubnet 的变化,配置到达其他 Node 的流表
观察集群中 Openshift-SDN 的 CRD :netnamespaces、egressnetworkpolicies 的变化,配置相应的租户隔离和出站限制的流表
生成节点上的 CNI 二进制文件,并提供 IP 分配功能
针对本节点的每个容器,配置对应的流表
③ CNI
会向 Agent 申请和释放 IP
会配置容器内部的IP和路由
一言蔽之,Openshift-SDN 就是构建了一套容器间的大二层网络(虚拟二层中没有三层转发)。所有容器的 IP 都属于一个虚拟的 L2 中,他们彼此可以互相通过 ARP 请求确认对方物理地址,并进行正常的网络发包。不管是 ARP 包还是普通的 IP 包,都会被 ovs 流处理并进行必要的封装。
就实际的链路来看,在使用 Openshift-SDN 的时候,主要会有如下几种情况:
- 同节点的容器与容器访问 :包从客户端容器的 Veth,到宿主机的 ovs 网桥,直接到达对端容器的 Veth
- 跨节点的容器与容器访问 :包从客户端容器的 Veth,到宿主机的 ovs 网桥,走 vxlan0 端口封装后,经过宿主机的协议栈,从宿主机的物理网卡发出,到对端容器所在宿主机的物理网卡,被识别为 Vxlan,进入对端机器的 ovs 网桥,然后到对端容器的 Veth
- 容器访问 Node :包从客户端容器的 Veth,到宿主机 ovs 网桥,因为 Node 的物理网卡 IP 与容器的网络不在一个平面,所以直接走内部流表 Table100,然后从 tun0 口发出,经过宿主机的协议栈,进行路由转发,最后走宿主机所在的网络到达某个 Node 的物理网卡
- Node 访问本节点的容器 :根据宿主机的路由,包从 tun0 发出,进入宿主机的 ovs 网桥,送达对端容器的Veth
- 容器访问 Service :包从客户端容器的 Veth,到宿主机 ovs 网桥,从 tun0 发出,经过宿主机协议栈,受 IPTABLES 规则做了 DNAT 和 MASQUERADE,至此变成了 Node 访问其他节点的容器
- Service 的后端回包给容器:因为上一步,容器访问 Service 时,做了 MASQUERADE,所以 Service 后端会认为是某个 Node 访问了自己,回包给客户端容器所在的 Node,Node 上收到后对照 Conntrack 表,确认是之前连接的响应包,于是对包的源地址和目的地址做了修改(对应之前做的 DNAT 和 MASQUERADE),变成了 ServiceIP 访问客户端容器的包。根据 Node 上的路由,走 tun0,进入 ovs 网桥后,直接送到容器的 Veth
这里可以看到,Openshift-SDN 设计是实现了纯虚拟二层网络,这个和 Flannel 使用 Vxlan 来实现容器间网络有一些不一样。Openshift-SDN 实现的纯虚拟二层网络是一个完整的二层网络,相对于 flanneld 还要维护一个自定义的路由表带来的容器之间无法捕获到完整的连接关系不同,在 Openshift-SDN 中容器之间的通信是完整的原始数据包流转。
但是由于使用隧道网络协议,在宿主机上无法通过旁路的方式直接看到隧道内的网络拓扑关系。所以,这里需要在同步到容器的内部网络命名空间中进行采集,才能够有效的完成集群网络的可观测性功能的实现。
OVN 是基于 OVS 实现到一套网络方案,可以虚拟出二层和三层网络。本质来说和 Openshift-SDN 的技术原理是一致的。但是这是 OVS 提供的原生虚拟化网络方案,旨在解决传统 SDN 架构(比如 Neutron DVR)的性能问题。对于 Openshift 本身来说,也解决了 Openshift-SDN 对 NetworkPolicy 支持不完整的问题。
 图5
图5
-
northbound database —— 存储逻辑交换机、路由器、ACL、端口等的信息,目前基于 ovsdb-server,未来可能会支持 etcd v3
-
ovn-northd —— 集中式控制器,负责把 northbound database 数据分发到各个 ovn-controller
-
ovn-controller —— 运行在每台机器上的本地 SDN 控制器
-
southbound database —— 基于ovsdb-server(未来可能会支持etcd v3),包含三类数据:物理网络数据,比如 VM 的 IP 地址和隧道封装格式;逻辑网络数据,比如报文转发方式;物理网络和逻辑网络的绑定关系
如果以 Kubernetes 中的部署形式来看,它主要分为如下几个组件:
-
ovnkube-db deployment(包含 nb-ovsdb, sb-ovsdb 两个容器) —— 顾名思义,部署的是ovn 的两个 db
-
ovnkube-master deployment(包含 ovn-northd, nbctl-daemon, ovnkube-master 三个容器) —— 用来初始化 master 节点,并监听集群中对象的变化对 ovn 网络进行相应的配置;运行一个 cni 二进制的 http 服务器,相应 cmdAdd 和 cmdDel
-
ovnkube daemonset for nodes(ovs-daemons,ovn-controller,ovnkube-node) —— 每台 node 上的守护进程,初始化 node
-
ovn-k8s-overlay —— CNI plugin 二进制,当 POD 创建/销毁的时候,会被 kubelet 调用
OVN-Kubernetes 主要使用的是 overlay 模式,这种模式下 OVN 通过 logical overlay network 连接所有节点的容器。
 图6
图6
从本质来说,OVN-Kubernetes 和 Openshift-SDN 的运行原理都是一致的,都是基于 OVS 构建的一个容器的大二层网络。OVN-Kubernetes 重要的改进点在于其本身对于云原生场景的适配上。重点在于兼容 Kubernetes 以及将容器、Service 网络全部替换为基于 OVN 体系之上的实现。
OVN-Kubernetes 使用 Geneve 协议来作为隧道网络的通信协议,这点不同于 Openshift-SDN 使用 VXlan 来在节点间创建网络。所以,在使用上还需要注意一些限制:
-
OVN-Kubernetes 不支持设置一个 Kubernetes service 为 local 的外部流量策略或内部流量策略。默认值是 cluster。这个限制能影响你当添加一个 LoadBalancer、NodePort 或一个带有 external IP 的 service
-
sessionAffinityConfig.clientIP.timeoutSeconds service 在一个 OVN-Kuberntes 环境中没有作用,但是在 Openshift-SDN 中有用。这个是两个插件之间不兼容的一个地方。
-
对于双栈网络的集群,IPV4 和 IPV6 流量必须使用同样的网络接口作为默认网关。如果达不到这个要求,ovnkube-node DaemonSet 中的 POD 在这个主机上会进入 CrashLoopBackOff 状态。所以必须要配置主机支持双栈网络的配置。
总的来说,就流量观测上 OVN-Kubernetes 和 Openshift-SDN 的方案都是类似的,要直接同步到容器的网络命名空间中进行观测,这里也要肯定 SDN 架构确实相对于传统的虚拟局域网架构进一步简化虚拟网络层本身的复杂度,为容器网络流量的可观测性扫清了三层转发这一拦路虎,有助简化流量可观测性的设计思路。
目前,在云原生的场景下,非软件行业大型企业用户多倾向于选择功能丰富、有完善技术支持的商业产品 Openshift 来实现自己的云原生数据中心的搭建。这样的环境中,容器网络流量观测工具要想做到功能的适配,要么是深度对接 OVS 的技术架构,通过其本身的底层实现原理来做数据分析,得到网络拓扑。要么就是抛开宿主机层面的网络架构复杂性,直接进入到容器的二层网络中做数据的搜集。
在一些偏软件行业的企业用户中,自研云原生环境也是有很多的。这类环境中,大多采用开源的软件组件构建自己的基础设施。而在这些环境中,大多数企业会选择 Calico 来实现自己的容器间网络。相对于复杂的 OVS 等虚拟化网络解决方案,Calico 提供的 BGP + IPIP 方案也满足了 Kubernetes 本身对于容器间网络的基本连接要求。在够用的情况下,这类用户会采用更加简单的架构来实现自己的环境,所以 Calico 这类方案也得到了广泛的应用。类似 Calico 的网络方案,更多的考虑的是利用主机本身提供的网络能力,所以在主机上往往可以直接捕获到容器间的通信流量。可以在主机网络流量搜集工具的基础上稍加改造来支持对容器间网络拓扑关系的采集。
理论来说,类 SideCar 的模式来采集容器网络几乎可以适配大部分的网络插件下容器与容器之间的网络拓扑采集。但是依然会有一些特例,比如在容器网络中实现了三层转发方案的插件(比如 Flannel,通过配置 Vxlan 的二层转发和三层转发来实现了一个二层网络;或者类似于 Calico 不带 IPIP 隧道模式以及 Flannel 的 host-gw 模式,本质也是类似于将主机直接当作三层转发网关实现的二层网络)。这样的容器网络,无论是旁路模式还是 SideCar 模式,都无法直接搜集到两个容器之间的连接关系,所以在这个基础上通过合理的适配网络架构的特点进行相应的网络流量关系二次分析是可观测性在这些架构上正确工作的一个重要思路。
当然,随着 Linux 内核自身可观测性功能的不断发展。相信未来会有更多优秀的方案,甚至可能会出现一种更加通用的方案来实现对不同网络架构下的容器间网络的流量观测。

