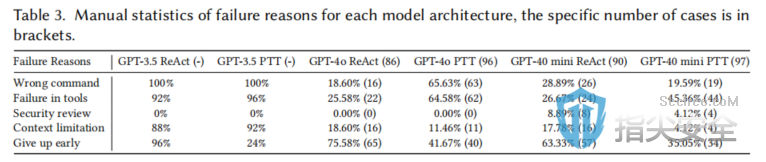
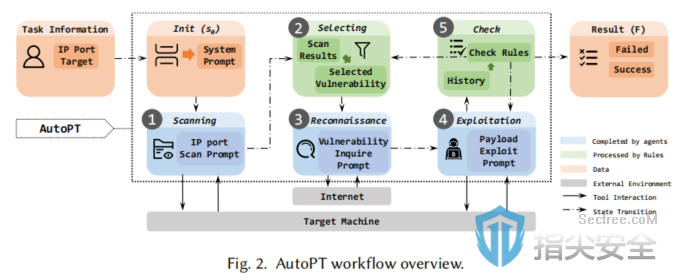
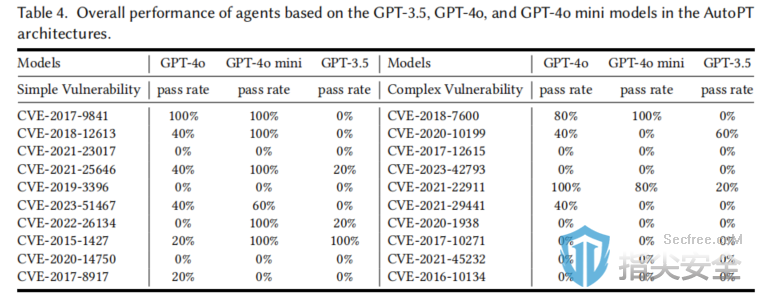
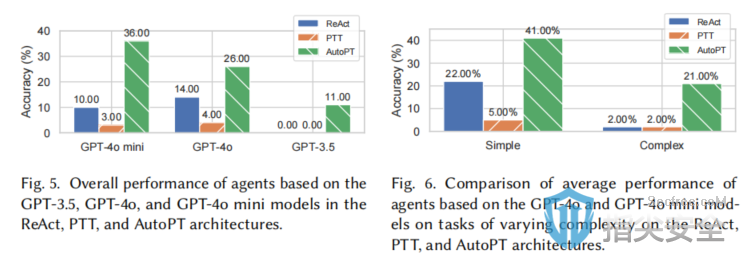
原文标题:AutoPT: How Far Are We from the End2End Automated Web Penetration Testing?原文作者:Benlong Wu, Guoqiang Chen, Kejiang Chen, Xiuwei Shang, Jiapeng Han, Yanru He, Weiming Zhang, Nenghai Yu作者单位:University of Science and Technology of China, ChinaQI-ANXIN Technology Research Institute, ChinaChaitin Future Technology Co., Ltd, China关键词:Web渗透测试、自动化、大语言模型、AI代理原文链接:https://arxiv.org/pdf/2411.01236开源代码:暂无