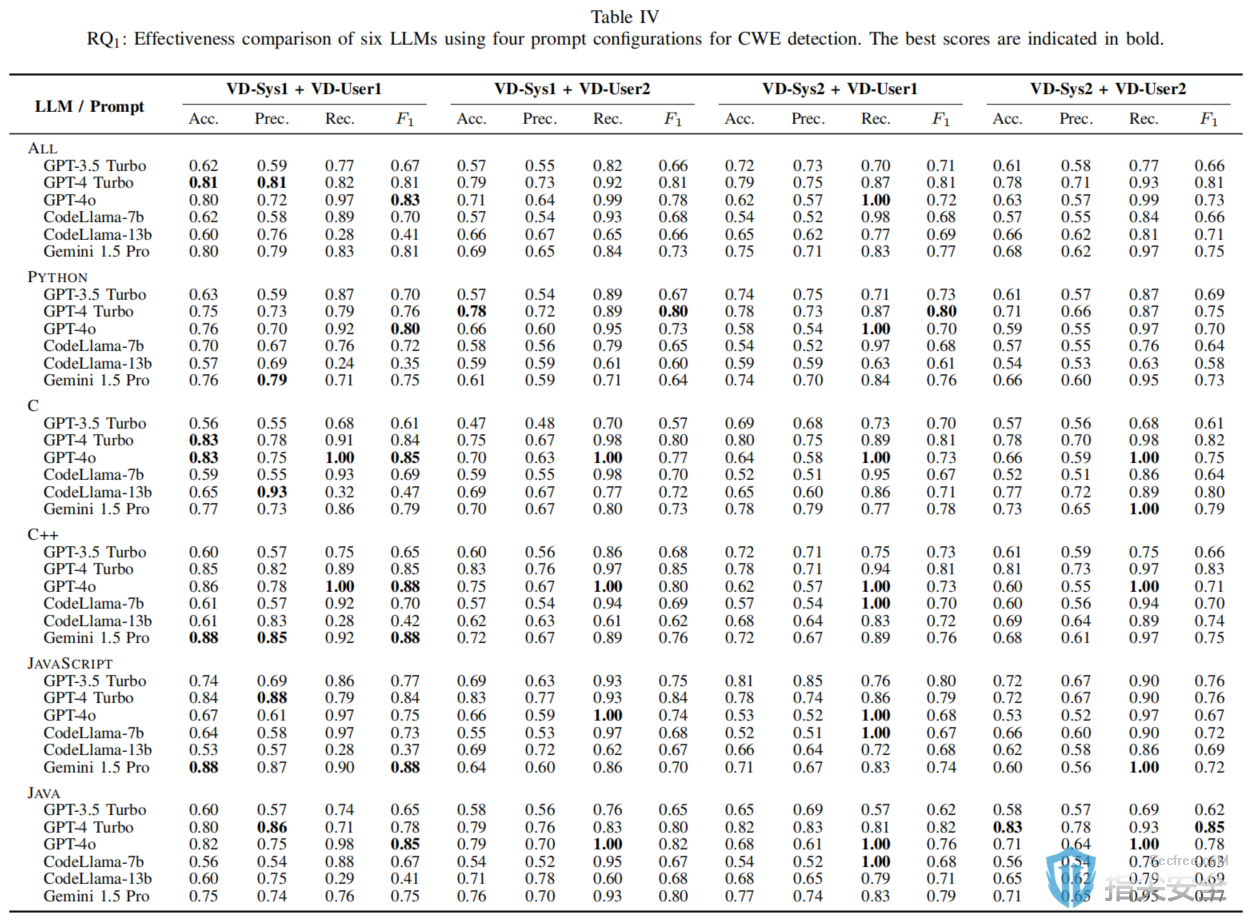
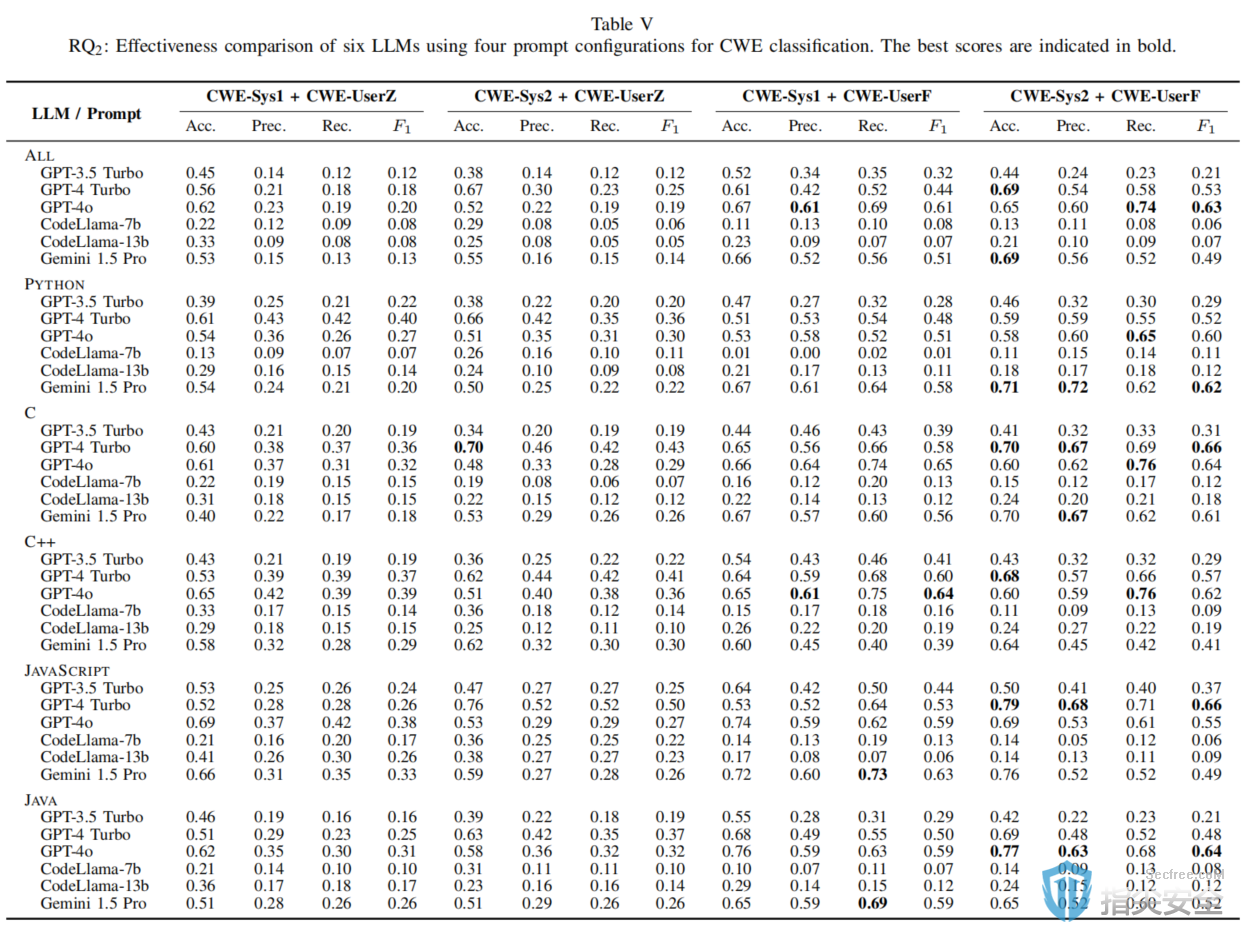
原文标题:Large Language Models for Secure Code Assessment: A Multi-Language Empirical Study原文作者:Kohei Dozono, Tiago Espinha Gasiba, Andrea Stocco作者单位:Technical University of Munich, Siemens AG, fortiss GmbH关键词:大语言模型(LLMs),安全代码评估,漏洞检测,多语言实证研究原文链接:https://arxiv.org/pdf/2408.06428v1开源代码:暂无