




释放双眼,带上耳机,听听看~!

基本信息
论文要点
引言
随着Chat-GPT的发布和检索增强生成(RAG)技术的兴起,大语言模型(LLM)能够通过简单的自然语言提示理解用户意图,综合企业内容并提供连贯的对话能力。然而,构建成功的企业聊天机器人需要精细设计RAG流程、微调LLM、确保企业知识的相关性和准确性、遵守文档访问控制权限、保护个人信息,并提供简洁且相关的响应。
本文分享了NVIDIA公司在构建企业级RAG聊天机器人方面的经验和策略,探讨了实现内容新鲜度、架构灵活性、成本效益、测试和安全性的方法。
案例研究
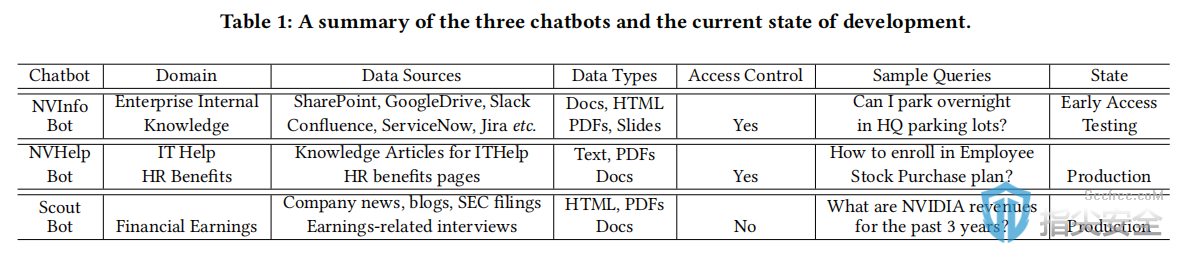
研究数据
此外,文档访问控制权限会增加搜索和检索过程的复杂性,需要仔细管理以确保数据安全和相关性。多模式内容还需要使用多模式检索器来处理结构化、非结构化和半结构化数据。解决这些挑战对于保持企业聊天机器人的准确性和可靠性至关重要。
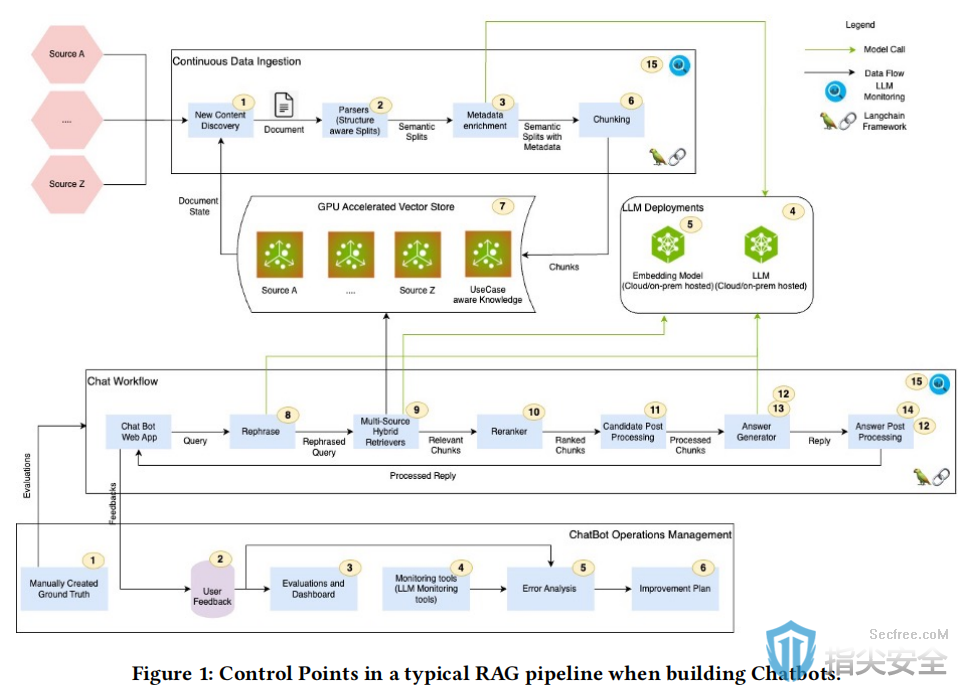
研究架构
研究挑战
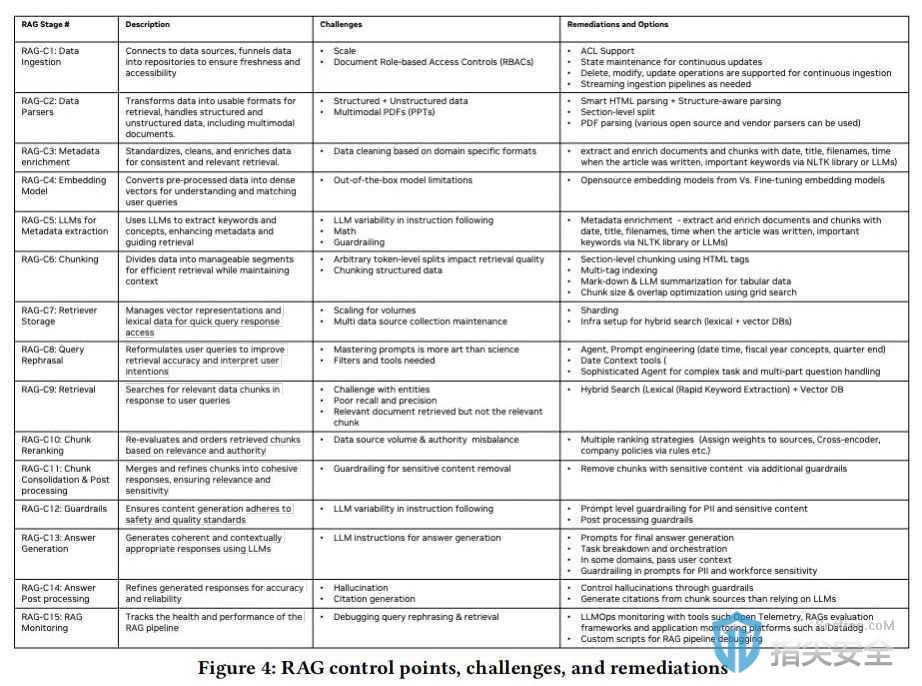
研究测试
论文结论
本文的贡献在于为构建安全、高效的企业级聊天机器人提供了实用解决方案,并指出了未来在处理复杂查询、优化RAG控制点和评估对话质量方面的研究方向。这些经验和方法对于推动生成式AI在企业环境中的应用具有重要意义。


