近日,安全极客与Wisemodel社区联合举办了“AI+Security”系列的首场线下活动,主题聚焦于“大模型与网络空间安全的前沿探索”。在这次活动中,月之暗面的安全工程师麦香先生发表了一场精彩的演讲,题为《月之暗面安全实践思考》。麦香先生深入解析了大模型安全所面临的挑战,提出了多层次的应对策略,并指出了目前大模型安全领域存在的一些关键痛点。
在信息技术迅猛发展的当下,大语言模型(LLM)已成为企业和组织不可或缺的工具。它们不仅极大地提升了信息处理的效率,还开辟了一系列创新的应用场景。然而,随着LLM应用的普及,其安全问题也日益凸显。麦香先生指出,本次分享的目的是深入探讨LLM在使用过程中可能遇到的安全风险,以及相应的应对策略。
大语言模型(LLM),例如广为人知的GPT,是一种经过训练的复杂神经网络,能够理解和生成类似人类的语言。它们基于马尔可夫模型的工作原理,通过接收输入并预测生成下一个最可能的单词。LLM通常被视为一个黑盒系统,它接收输入,访问数据,并产生用户可控的输出。在使用LLM时,需要注意它与应用程序中可能集成的任何云API一样,调用了周围的信任边界。在LLM的运作中,数据预处理非常关键,类似于准备火锅前的食材处理。超参数则相当于火锅中的调味品,它们共同决定了最终的输出质量。这意味着,就像烹饪一样,LLM的输出质量也依赖于精心的数据准备和参数调整。
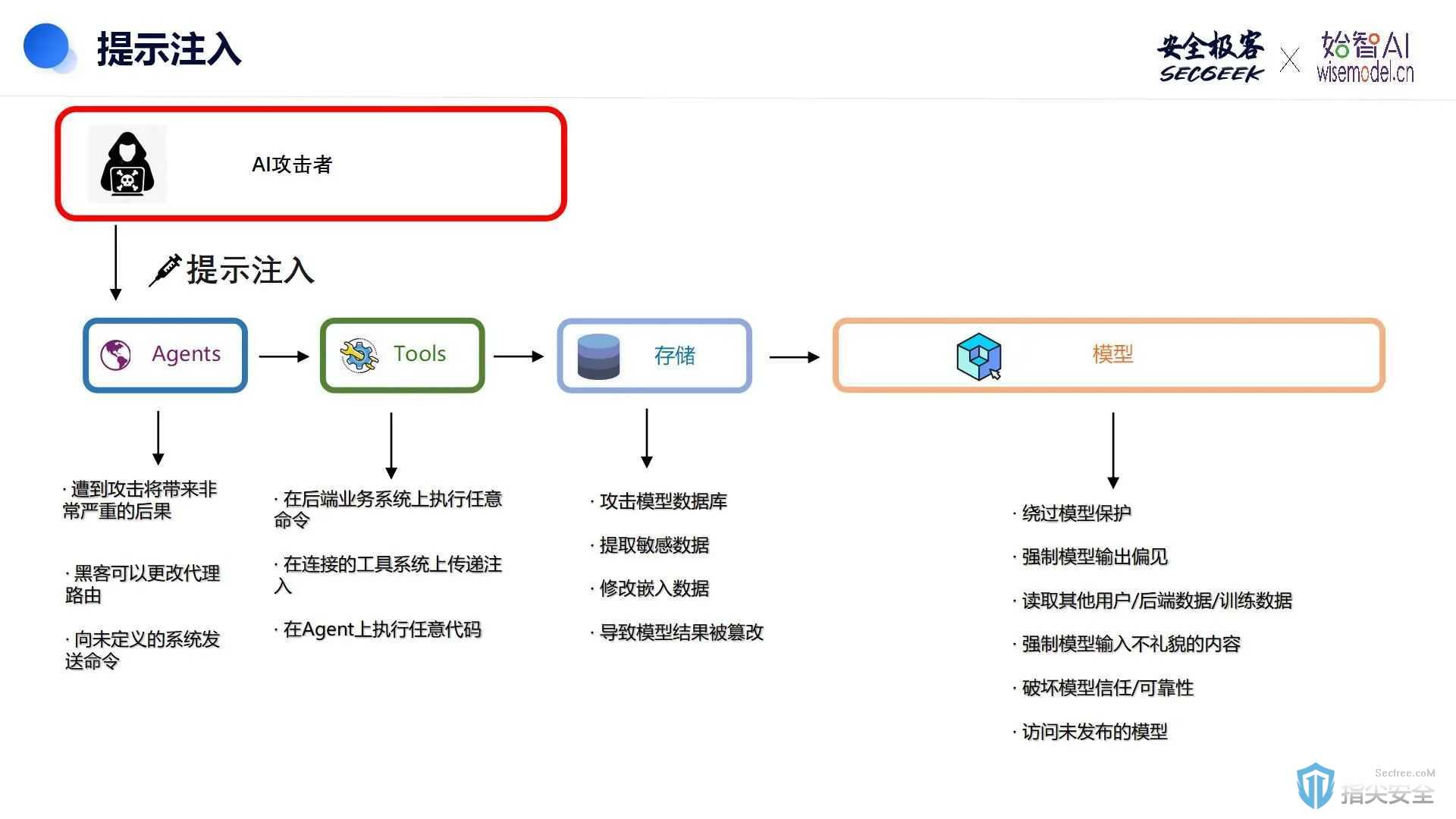
大语言模型(LLM)虽然功能强大,但它们也面临着众多安全挑战。在这些挑战中,我们尤其需要关注以下四个主要风险领域:数据安全、模型安全、内部威胁以及法律法规的遵守和未来合规要求。特别需要注意的是,Agent由于拥有大量个人信息和访问权限,一旦遭受攻击,可能会带来灾难性的后果。
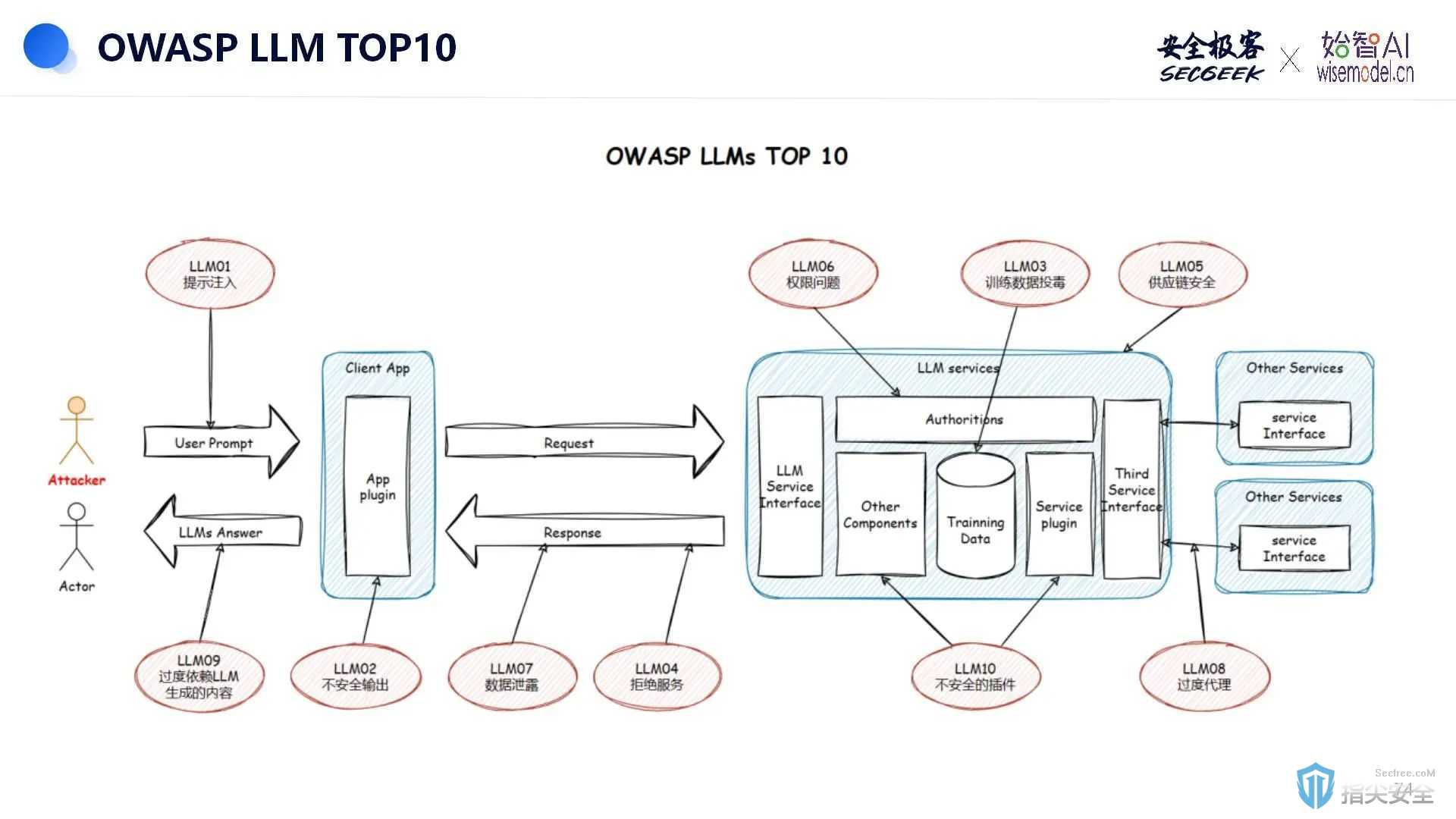
根据OWASP的总结,以下是LLM面临的TOP10安全风险:
1. 提示注入攻击:攻击者可能通过精心设计的输入来操纵受信任的LLM,导致即时注入漏洞。
2. 不安全的输出处理:如果插件或应用程序在接受LLM输出时缺乏安全控制,可能会引发XSS、CSRF、SSRF、权限提升、远程代码执行等安全问题,甚至代理劫持攻击。
3. 训练数据中毒:LLM在学习过程中存在训练数据被污染的风险,这可能会导致向用户提供错误信息。
4. 模型拒绝服务:攻击者通过与LLM交互消耗大量资源,从而降低用户体验并增加资源成本。
5. 供应链漏洞:LLM应用程序的供应链漏洞可能影响整个应用生命周期,包括第三方库/包、Docker容器、基础镜像以及服务供应商。
6. 敏感信息披露:LLM可能在其响应中意外泄露敏感信息、专有算法或其他机密细节,导致数据或知识产权的未经授权访问,侵犯隐私。
7. 不安全的插件设计:LLM插件作为自动调用的扩展,如果应用程序无法控制执行,可能会遭受恶意请求,导致远程代码执行等不良行为。
8. 过度代理:LLM与其他系统接口时,如果代理不受限制,可能会导致不良操作。LLM不应自我监管,API中必须嵌入控件。
9. 过度依赖:过度依赖LLM可能会导致错误信息或不当内容,如果没有适当的监督,可能会引发用户口碑问题或其他风险。
10. 模型盗窃:如果专有LLM遭到破坏、被盗、被复制,或者模型使用的权重和参数被提取以创建功能等效模型,就会发生模型盗窃。
针对大语言模型(LLM)所面临的安全风险,可以采取以下一系列防护措施:
1. 提示注入防御:部署启发式策略和智能防御机制,以检测和阻止恶意输入。同时,在提示注入和后续处理环节中加强安全检查。
2. 控制不安全输出处理:在LLM生成输出时,采取严格的安全控制措施。此外,对生成的数据执行严格筛选,确保输出的安全性。
3. 防止训练数据中毒:确保数据来源的合法性和安全性,并采用适当的数据清洗方法以移除恶意内容。同时,实施措施以防止恶意输入对模型造成影响。
4. 防止模型拒绝服务(DoS):通过限制用户请求频率来避免资源过度消耗,并优化资源使用以保持服务的稳定性。
5. 防范供应链漏洞:定期进行基线环境的安全检查,并定期对第三方库和容器执行安全扫描,同时确保输入数据的合法性和敏感数据的保护。
6. 防止敏感信息披露:实施数据分类和隐私保护措施,以防止敏感信息泄露。对敏感数据进行屏蔽处理,以避免在响应中泄露。
7. 安全的插件设计:确保插件的安全性,并能够及时反馈恶意行为。在软件开发生命周期中加入安全培训和威胁建模,以确保插件的安全性。
8. 防止过度代理:采用授权模型和反馈捕获机制,以确保代理行为的安全性。
9. 减少过度依赖LLM:在多个层面实施及时防护和基础保护,确保模型输出符合用户预期。加强身份验证措施,如实施多因素身份验证(MFA),并进行审计跟踪。
10. 防止模型盗窃:通过加密和访问控制来保护模型的核心数据。加强模型使用的管理和监控,以防止未经授权的访问。
为了确保大语言模型(LLM)在其整个生命周期中的安全性,必须从训练到部署采取全面的安全措施。这些措施涵盖数据安全、模型训练、模型完整性和模型测试等多个方面,同时在实际操作中应用多种安全实践,以保障模型的安全和可靠性。
数据安全是LLM应用的基础,确保数据的合法性和安全性是首要任务。此阶段,选择可信的数据来源,避免使用未经验证的数据源。同时,采用适当的方法对数据进行清洗,去除潜在的恶意内容,确保数据的纯净和安全。实施数据的安全存放和加密传输,防止数据在存储和传输过程中被截取或篡改。
在模型训练阶段,需要保证训练环境的基础设施安全,包括硬件和软件的安全配置。严格控制训练数据的访问权限,确保只有授权人员可以访问和使用训练数据。此外,在模型开发的各个阶段嵌入安全实践,确保模型开发过程中的每一步都符合安全标准。
通过加密和访问控制,保护模型的参数,防止其被恶意修改。同时,定期检查和审计供应链中的组件和依赖,防止外部依赖的漏洞影响模型。
在模型部署前,需要评估模型的性能和安全性,通过灰度测试逐步验证模型在实际环境中的表现。并且,持续监控数据的变化,及时优化模型,确保其在动态环境中的适应性和安全性。
为了增强LLM的安全性,以下实践可以在实际操作中应用:
-
传输加密:在数据传输过程中使用加密技术,确保数据不被截取和篡改。
-
数据分类和RBAC(基于角色的访问控制):根据数据的敏感程度进行分类,并实施基于角色的访问控制,确保敏感数据仅被授权人员访问。
-
数据备份与恢复:定期备份数据,并制定数据恢复计划,确保在发生安全事件时能够迅速恢复数据,减少损失。
-
多因素身份验证(MFA)和密钥管理:加强对系统的身份验证和密钥管理,防止未经授权的访问,提高系统的整体安全性。
-
输入控制和应用访问控制:严格控制输入数据和应用程序的访问,防止恶意输入和攻击行为,对所有输入进行验证,确保其合法性和安全性。
大语言模型(LLM)的安全防护不仅涉及技术层面的措施,还需要全方位的策略和管理体系。通过多层次的防护措施,可以有效应对LLM在应用过程中面临的各种安全风险,确保模型的安全性和可靠性。
未来,随着技术的发展和应用场景的拓展,LLM安全实践也需不断迭代和优化,以应对新的挑战和威胁。只有这样,才能真正发挥LLM的潜力,为企业和组织带来更大的价值。
“AI+Security”系列第二期专题分享嘉宾火热征集中。我们诚挚邀请来自人工智能(AI)和网络安全领域的行业专家与领军人物,共同参与分享。一起深入探讨并分享关于”AI+Security”技术理念的见解和经验。我们期待您的加入,一起推动AI与安全技术的融合与创新。