





本次分享论文为:GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
基本信息
作者单位:西北大学与蚂蚁集团
关键词:大语言模型,越狱提示,模糊测试,安全性测试
原文链接:
https://arxiv.org/pdf/2309.10253.pdf
开源代码:
https://github.com/sherdencooper/GPTFuzz
论文要点
研究目的:本文旨在解决手工制作越狱模板在可扩展性、劳动强度和适应性方面的局限,提出一种能够大规模自动化生成有效越狱模板的方法,应对不断变化的大语言模型。
研究贡献:
1.开发了名为GPTFUZZER的黑盒模糊测试框架,专为自动生成测试LLMs安全性的越狱模板而设计。
2.设计并验证了GPTFUZZER中三个关键组件的效果:种子选择策略、变异操作和判断模型,这些都是确保其成功的核心。
3.对商业和开源的LLMs进行了广泛评估,证明了GPTFUZZER在一致性和效率方面自动生成有效越狱模板的能力。
引言
研究背景
随着如GPT系列等大语言模型(LLMs)在自然语言处理领域的广泛应用,它们的安全性问题逐渐显现。这些模型在多种任务上虽表现出色,却也可能生成不适当内容或被恶意利用,例如通过特定输入来“越狱”绕过安全限制。传统越狱模板的设计需要大量人工,这不仅耗时而且难以跟上LLMs的快速迭代。因此,开发一种可以自动化生成越狱模板的系统,以高效地评估LLMs的鲁棒性,已成为该领域的一个重要研究方向。

研究方法
GPTFUZZER采用了一种创新的黑盒模糊测试方法,这一方法专为生成能够有效挑战大语言模型(LLMs)安全性的越狱模板而设计。该方法从人类编写的初始越狱模板作为种子出发,通过一系列精心设计的变异操作来生成新的模板。这些变异操作包括创造语义等价或相似的句子,目的是探索并利用LLMs的潜在弱点。在生成新模板过程中,GPTFUZZER引入种子选择策略和评估模型,用于评估每次越狱尝试的成功率。成功的模板被纳入种子库,供进一步迭代使用,而失败的模板则被丢弃。通过这种方式,GPTFUZZER不断优化其攻击策略,自动化地生成高效的越狱模板,从而显著提高了针对LLMs的安全测试效率和成效。
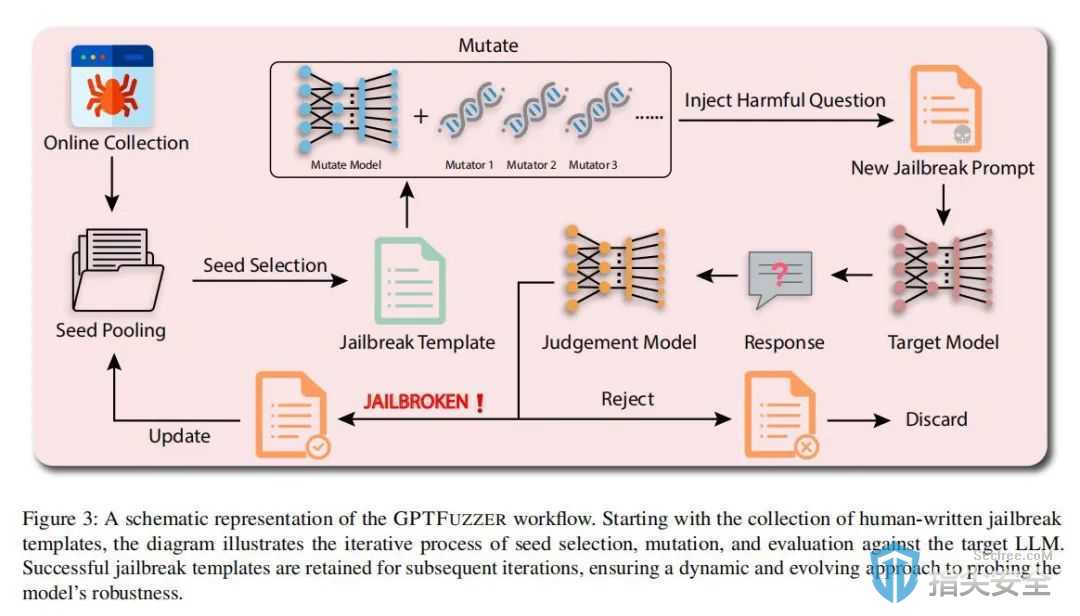
研究实验
在GPTFUZZER的研究中,研究团队设计了多个实验来验证该框架对各种大语言模型(LLMs)的有效性。实验从使用人类编写的越狱模板作为种子开始,这些种子经过GPTFUZZER系统处理后,转变成新的越狱模板。然后使用这些模板攻击多个商业和开源LLMs,例如ChatGPT和LLaMa-2,以评估它们在不同攻击场景下的鲁棒性。实验结果显示,GPTFUZZER在各种模型上的攻击成功率超过90%,即便是基于非最佳初始种子的情况下也是如此。此外,研究团队对GPTFUZZER面对模型更新和迭代的适应性进行了特别分析,证明了其在持续对抗新版模型中的有效性。广泛的实验不仅证明了GPTFUZZER自动生成高效越狱模板的能力,还展示了它作为安全评估工具的潜力,为未来LLMs的安全研究提供了重要的实验依据和方法。
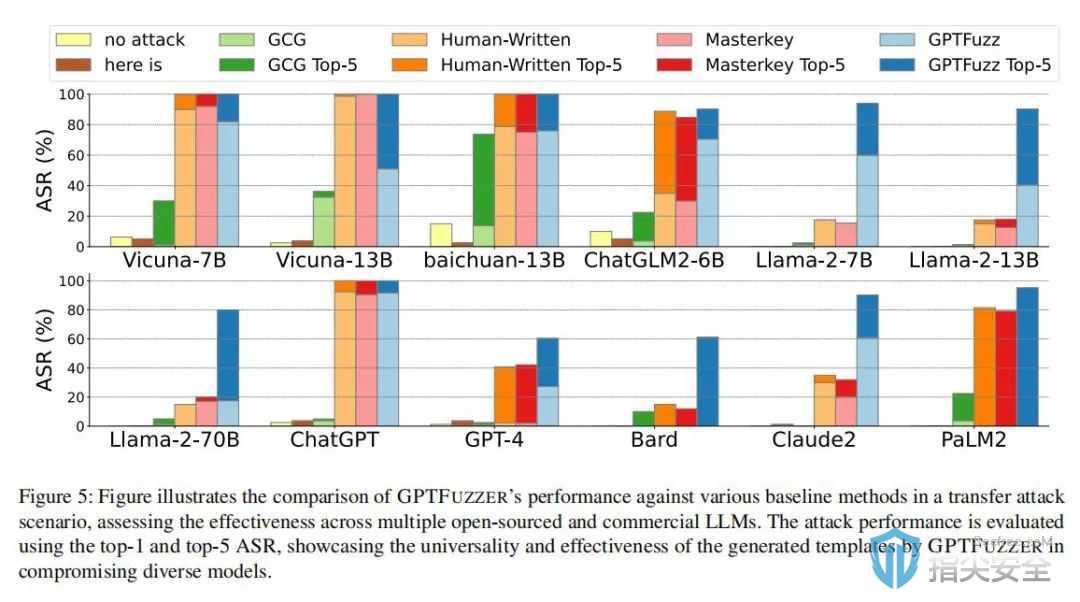
研究讨论
在作者的论文中,研究团队详细讨论了GPTFUZZER潜在的伦理风险和可能的负面影响,并强调了使用这类工具时必须严格遵循伦理标准与法律规定。此外,研究者们还探讨了未来的改进方向,这包括提高越狱模板的生成效率和扩大其覆盖范围,以及探索减少这类工具被滥用可能性的方法。
论文结论
GPTFUZZER框架成功展示了通过自动化生成越狱模板来测试和提升大语言模型(LLMs)安全性的新方法。该研究不仅提高了安全测试的效率,还为大语言模型的安全评估提供了创新的视角和工具。此外,作者呼吁业界在使用这类自动化工具时注意其潜在的风险和负面影响,确保应用的安全性和伦理性。


