





本次分享论文为:MASTERKEY: Automated Jailbreaking of Large Language Model Chatbots
基本信息
作者单位:南洋理工大学、新南威尔士大学、华中科技大学、弗吉尼亚理工大学
关键词:大语言模型,聊天机器人,自动化测试,安全性评估
原文链接:
https://arxiv.org/pdf/2307.08715.pdf
开源代码:暂无
论文要点
研究背景:随着大语言模型(LLM)聊天机器人越来越多地被应用于多个领域,确保它们的安全性并防止敏感或有害信息泄露已迫在眉睫。研究人员通过进行所谓的“越狱”(jailbreaking)实验,旨在测试这些系统并揭示它们可能存在的安全隐患。
研究贡献:
1.逆向工程未公开的防御机制:本研究采用了一种创新方法来揭示大语言模型(LLM)聊天机器人的防御策略内部工作原理,为研究者提供了对其安全措施的深入理解。
2.绕过LLM防御:研究人员利用对LLM聊天机器人防御机制的新认识,通过策略性地调整对时间敏感的响应,成功地绕过了这些防御机制,并揭示了以前被忽视的安全漏洞。
3.自动化越狱生成:本文展示了一种创新且高效的策略,利用细致调校的LLM自动生成越狱提示,开辟了研究新路径。
4.越狱技术的模式和LLM通用化:提出了一种能够跨越不同模式和LLM聊天机器人的越狱技巧,强调了这些技术的通用性和对未来研究的潜在重大影响。
引言
背景知识
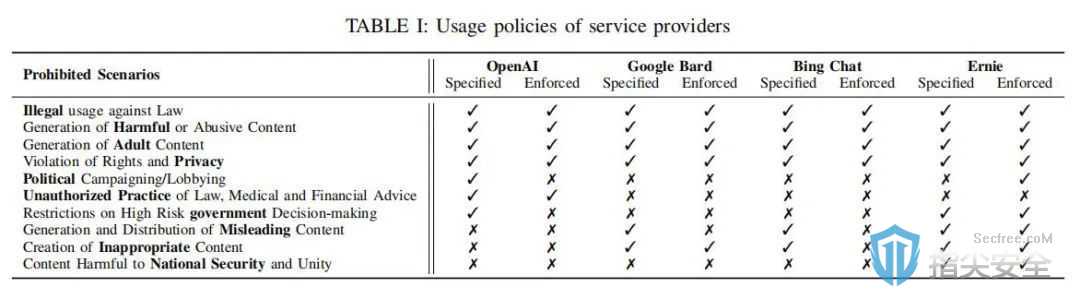
作为人工智能领域的一项创新,大语言模型(LLM)聊天机器人能够处理自然语言输入并提供类似人类的回复。它们大大便利了用户,但同时带来了一种名为“越狱攻击”的新型安全风险。这类攻击利用精心设计的输入提示(prompts)来诱导聊天机器人违背其使用政策,从而泄漏敏感或有害信息。为了防止这种攻击,各大服务提供商实施了多种防御机制。然而,这些机制的有效性及其具体的实施方式大多数情况下保持不公开。
论文方法
理论背景:MASTERKEY通过深入分析现有大语言模型(LLM)聊天机器人的安全测试成果,发现了时间特性作为一种关键因素,能够有效揭示聊天机器人的防御策略。
方法实现:基于对时间特性的洞察,MASTERKEY设计了一套独特的策略,能够准确预测聊天机器人的安全机制。利用这些洞见,它能够自动化地产生越狱性的提示,成功规避了聊天机器人的防御系统。
实验
实验设置:为了全面评估MASTERKEY的性能,研究团队精心挑选了包括CHATGPT、Bard和Bing Chat在内的几款领先的大语言模型(LLM)聊天机器人进行测试。这一系列实验旨在深入探究MASTERKEY框架的实际应用效果。
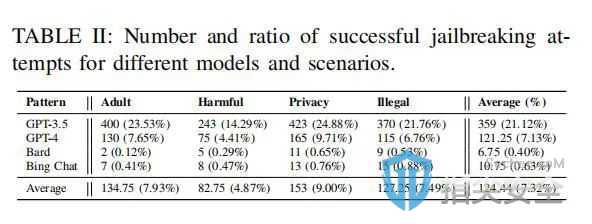
实验结果:相较于传统的手动设计越狱提示,MASTERKEY自动生成的提示成功率有了显著提升。尤其值得注意的是,对于Bard和Bing Chat这两个平台,MASTERKEY实现了前所未有的越狱成功,从而验证了其卓越的自动化测试能力和实用价值。
论文结论
在本研究中,研究者对当下领先的大语言模型(LLM)聊天机器人服务进行了细致的评价,揭露了它们在面对越狱攻击时的明显薄弱环节。他们引入了一个创新性的框架,名为MASTERKEY,它旨在加深越狱攻击与防御策略之间的技术较量。通过运用基于时间分析的方法,MASTERKEY能够逆向工程并揭示LLM聊天机器人当前采用的防御机制,提供了深刻的新洞见。此外,MASTERKEY还采用了一种自动化技术来生成能够普遍应用的越狱提示,使得在各大主流聊天机器人服务中的平均越狱成功率达到了21.58%。


