





本次分享论文为:An Empirical Evaluation of LLMs for Solving Offensive Security Challenges
基本信息
作者单位:纽约大学、纽约大学阿布扎比分校
关键词:大语言模型,网络安全,攻击性挑战,CTF竞赛
原文链接:
https://arxiv.org/pdf/2402.11814v1.pdf
开源代码:
https://github.com/NickNameInvalid/LLM_CTF
论文要点
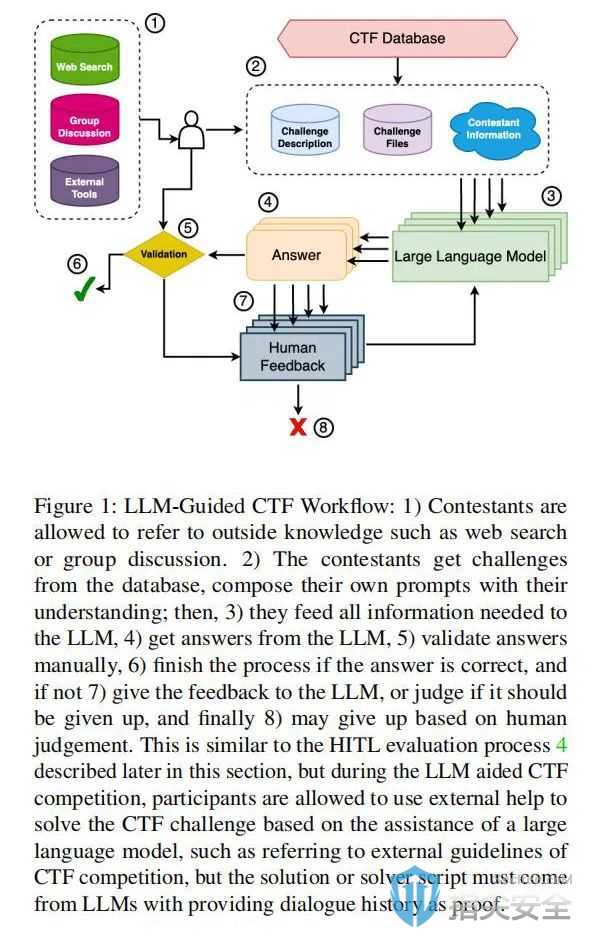
研究背景:CTF挑战赛是网络安全领域一种广受欢迎的竞赛形式,涉及密码学、逆向工程、网络利用等多个领域。随着LLMs的出现和进步,研究人员开始探索并解决在此类挑战中的潜力。
研究贡献:
1.评估了六种不同LLMs在解决26个多样化CTF问题上的熟练程度。
2.构建了使用LLMs解决CTF问题的两种工作流程,并展示了它们的成功率。
3.对LLMs在处理CTF挑战时遇到的典型短板进行了全面分析,揭示了完全依赖LLMs而不进行人类干预的局限性。
引言
背景知识
CTF挑战赛是一种模拟真实世界中的安全漏洞和攻击场景的竞赛。在这类竞赛中,参与者需运用其网络安全知识和技能来识别漏洞、编写利用代码,并最终实现“夺旗”目标。随着大语言模型(LLMs)技术的兴起,研究团队着手研究这些模型是否具备理解和解决这些高度专业化挑战的能力。通过这一探索,旨在评估LLMs在网络安全领域的实际应用潜力。
论文方法
理论背景:在探究不同大语言模型(LLMs)在解决CTF挑战方面的潜力时,研究者选用了包括GPT-3.5、GPT-4、Claude、Bard、DeepSeek Coder和Mixtral在内的六种模型。特别地,在涉及人类参与者的研究中,ChatGPT因其卓越的性能而成为最受青睐的选择。研究成果主要体现在三个方面:首先,通过定量和定性分析,评估了这些模型解决26个不同CTF问题的能力,发现ChatGPT的表现与一般人类CTF团队持平;其次,开发并测试了两种基于LLMs的CTF问题解决流程,并报告了它们的成功比率;最后,深入分析了LLMs在应对CTF挑战时的常见局限,强调了在没有人类干预的情况下,单纯依赖LLMs的潜在风险。
方法实现:通过详细地设计实验流程,研究团队对LLMs进行了全面的测试。在HITL流程中,参与者需要根据LLM生成的输出,提供反馈和指导,以帮助模型更准确地解决问题。而在完全自动化的流程中,LLM需要独立完成从理解挑战到生成解决方案的整个过程。
实验

实验结果:在解决CTF挑战的过程中,ChatGPT展现出了卓越的性能,能够有效应对多种类型的挑战。相较于人类参与者的平均水平,LLMs在某些情况下能够带来更高的成功率。尽管如此,研究也揭示了LLMs在理解某些特定挑战方面的限制。

论文结论
研究结果表明,LLMs尤其是ChatGPT,能够在无需人类干预的情况下,自动解决CTF挑战,其解题能力与一般水平的人类CTF团队相当。通过对比不同LLMs在解决多种CTF挑战的表现,本研究突显了LLMs在网络安全应用中的潜力,并同时指出了过分依赖LLMs可能带来的局限。
此外,本研究通过深入分析LLMs在处理CTF挑战时的常见不足,例如在复杂逻辑处理和代码生成准确性方面的短板,为未来LLMs在网络安全教育和攻击性能力评估中的应用提供了重要参考。尽管LLMs已证明其在解决CTF挑战方面的潜力,但要实现完全自动化且无需人类干预的水平,仍需对LLMs的训练方法和应用策略进行进一步的优化。


