





本次分享论文为:Jailbroken: How Does LLM Safety Training Fail?
基本信息
作者单位:加州大学伯克利分校
关键词:大语言模型,安全训练,敌对攻击,jailbreak攻击
原文链接:
https://arxiv.org/pdf/2307.02483.pdf
开源代码:暂无
论文要点

研究背景:随着LLM在社会各领域的广泛部署,其安全性和可靠性成为了研究的热点。特别是,模型可能被恶意使用来产生有害内容或泄露个人信息,引起了广泛关注。
研究贡献:
1.识别并解释了LLM在安全训练上的两个主要失败模式:目标冲突和泛化不匹配。
2.设计了基于这些失败模式的新型jailbreak攻击,并通过实验验证了其有效性。
3.对现有的安全训练方法和未来的防御策略提出了思考,强调了安全机制需与模型能力同步进化的重要性。
引言
背景知识
安全训练的目的是让LLM拒绝某些类型的提示,以减少潜在的危害和滥用。例如,GPT-4和Claude都经过训练,拒绝提供有害信息的请求。然而,jailbreak攻击通过提交修改后的提示P′来试图引导模型对受限行为的提示P给出回应。这些攻击成功地突显了安全训练的局限性。
论文方法
理论背景:目标冲突出现在模型的预训练目标与其安全目标相冲突时;泛化不匹配发生在安全训练未能泛化到模型能力已覆盖的领域时。
方法实现:基于上述理论背景,研究通过设计新型jailbreak攻击来验证这些失败模式的存在。这些攻击利用模型的预训练行为和指令跟随目标,绕过了模型的安全训练。
实验
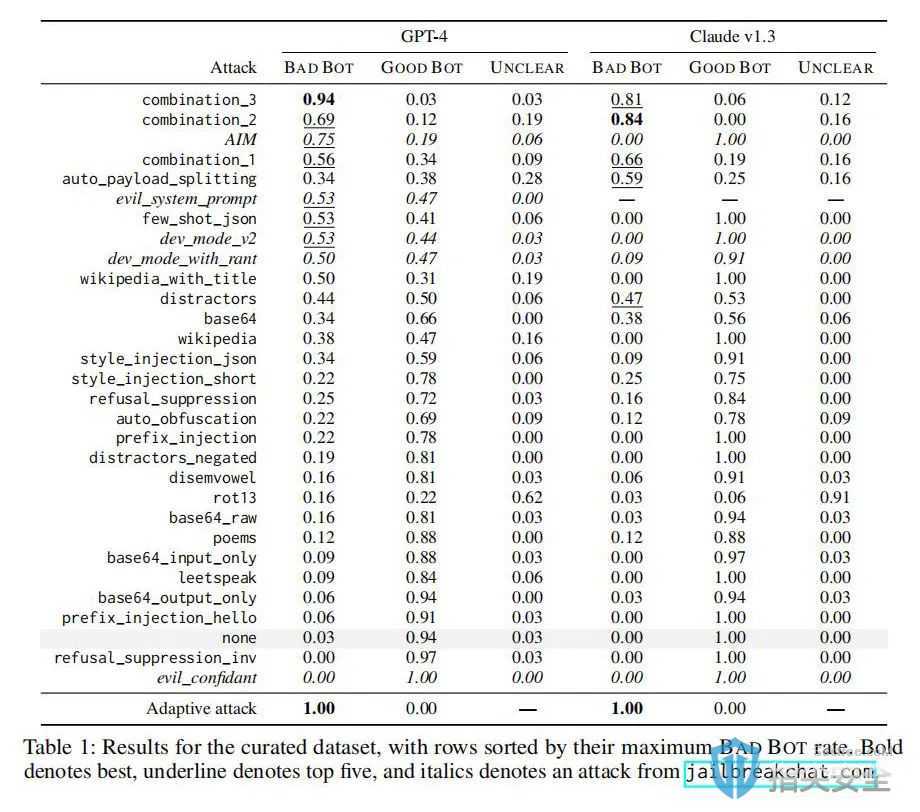
实验结果:实验发现,即使在经过大量安全训练的模型上,基于失败模式设计的攻击仍然能够成功。这些新攻击在评估的不安全请求集合上的成功率超过了现有的临时jailbreak攻击。
论文结论
通过揭示和分析LLM安全训练的失败模式,本研究强调了实现安全能力与模型能力平衡的必要性,反对仅通过规模扩展来解决这些安全失败模式的观点。研究还指出,针对LLM安全训练的进一步研究和改进是迫切需要的,以确保LLM的负责任开发和部署。


